分析解析项目上内存泄漏、频繁GC、cpu飙升问题
问题背景
我们的 Java 服务都是封装在 Docker 容器里运行的,今天早上到公司发现有个服务内存跑满,CPU 100%~500% 之间跳动,第一时间想到的是 dump 快照到本地进行分析。
这是本人首次在容器内分析线上问题,遇到几个坑,特此记录下来!
分析过程
通过容器监控工具发现 A 容器内存和 CPU 占用都不正常:

安装 Arthas
本来选择使用 jvm 自带的分析工具进行内存分析,但是我们所有的 Java 服务镜像都是基于 anapsix/alpine-java:8_server-jre_unlimited 构建的,此镜像默认是没有 jvm 分析工具,故选择阿里的 Arthas 线上监控诊断产品进行分析:
1 | BASH |

坑 1:提示无法找到可用的 Java 进程
主要是因为基础镜像是 jre,arthas 无法 attach 目标进程,只需要安装一个 openjdk8 即可解决问题:
1 | BASH |

坑 2:提示无法获取 LinuxThreads 管理器线程
arthas 无法获取 PID 1 的线程,原因及解决方案如下:
为什么 Docker 中运行的 Java 进程 PID 为 1?
在 Linux 上有了容器的概念之后,一旦容器建立了自己的 Pid Namespace(进程命名空间),这个 Namespace 里的进程号也是从 1 开始标记的。所以,容器的 init 进程也被称为 1 号进程。你只需要记住:1 号进程是第一个用户态的进程,由它直接或者间接创建了 Namespace 中的其他进程。
每个 Docker 容器都是一个 PID 命名空间,这意味着容器中的进程与主机上的其他进程是隔离的。PID 命名空间是一棵树,从 PID 1 开始,通常称为 init。
注意:当你运行一个 Docker 容器时,镜像的 ENTRYPOINT 就是你的根进程,即 PID 1(如果你没有 ENTRYPOINT,那么 CMD 就会作为根进程)。
可以看到,启动 arthas 之后,提示没有找到可用的 java 进程 PID,这是因为容器内只有 Java 一个进程,通过 ps 查看 PID 为 1,而 PID 1 是特殊的进程号,不会处理任何信号。所以我们要让 Java 进程的 PID 不为 1。可以使用 tini 占用 PID 1,我们在容器中启动 init 系统有很多种,这里推荐使用 tini,它是专用于容器的轻量级 init 系统,用起来也很简单,只需要在原来的 Dockerfile 中添加一段 ENTRYPOINT,用于启动 tini 进程即可:
1 | BASH |
添加之后重新启动容器,可以发现 PID 1 已经是 tini 进程了,而 Java 进程变成了 PID 7!

再重复之前的操作,使用 arthas 进行 attach 目标进程,成功进入到 arthas 的命令行:
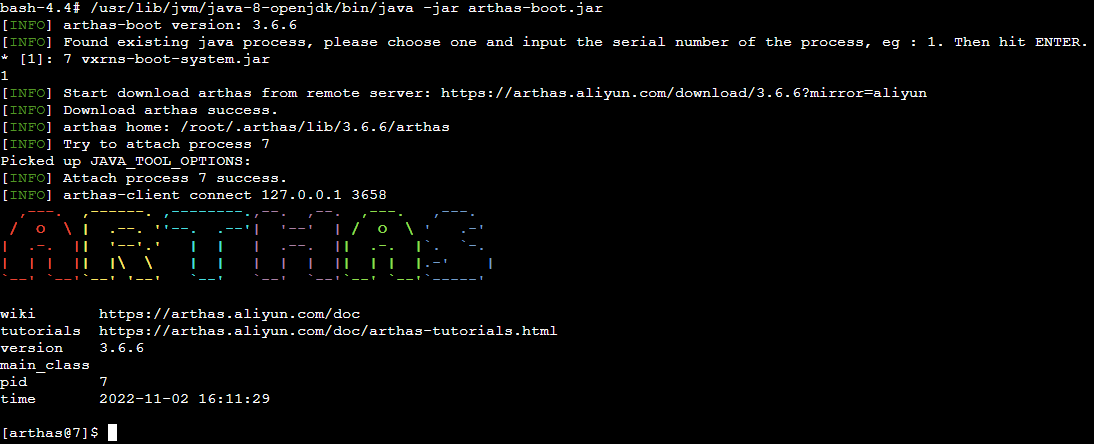
使用 Arthas 诊断问题
诊断内存问题
使用 arthas 的 dashboard 命令查看当前系统的实时数据(默认 5s 刷新一次,可以通过 -n 参数设置)
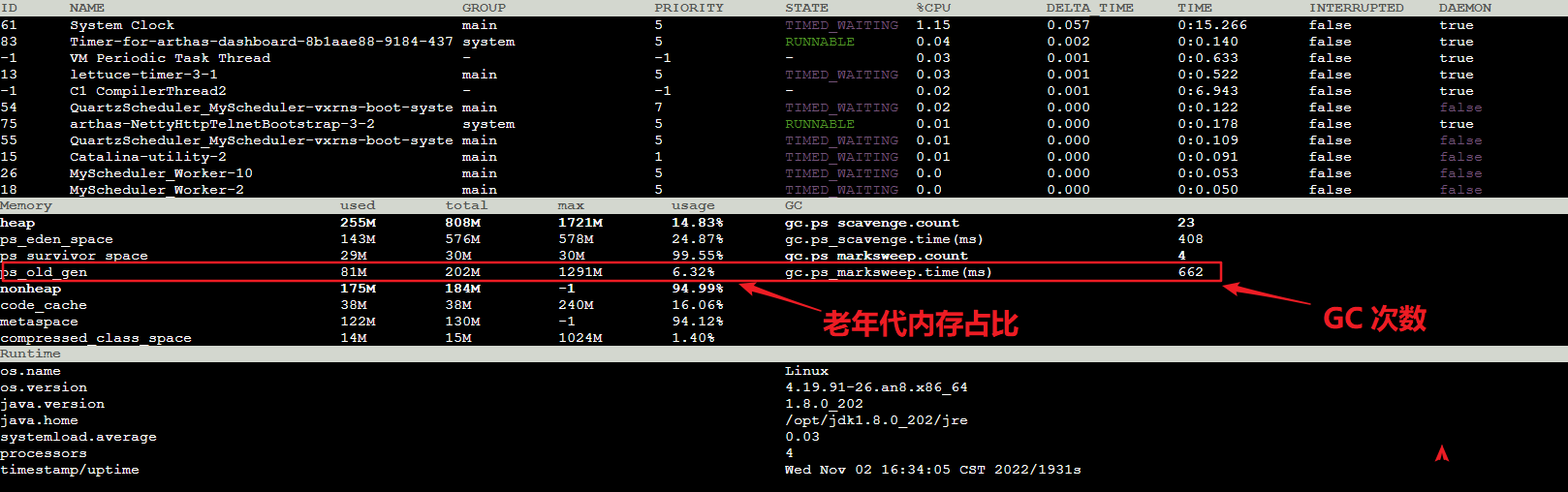
此处截图只是正常情况下的,今天出现问题时老年代内存占比达到 百分之 90 以上,Full GC 次数也多得恐怖,说明有大量的 GC 线程在运行,这么多次 GC 的情况下,那些垃圾还没被清理掉,说明系统已经出现了内存泄漏,接下来的工作就是找到那些还未被清理的垃圾究竟是什么对象,然后解决掉!
要分析堆内存中有那些对象,需要使用到 arthas 的一个工具(heapdump),这个工具的作用类似于 jdk 的 jmap,都是转储堆内存快照,命令如下:
1 | BASH |

导出的 dump.hprof 是 Java 的内存快照文件(Heap Profile),咱们可以借助一些工具分析内存快照,比如:JProfiler、JDK 自带的 jhat 和 jvisualVM。我这里选择使用 JProfiler。

由此结果可以看到,Date 对象一直无法回收,个数达到了 2亿 多,代码里可能出现了死循环,不停地创建 Date 对象,只增不减,导致内存泄漏!
诊断 CPU 问题
通过分析内存快照,猜测可能是死循环导致的内存泄漏,死循环导致 CPU 居高不下,通过 Arthas 分析占用 CPU 高的线程,定位到具体代码片段,结合上面内存分析结果针对性地解决问题。
通过 arthas 的 thread 命令,查看当前系统的线程(默认查看第一页,按 CPU 增量时间降序排序)
1 | BASH |
此处截图是正常情况下的线程信息
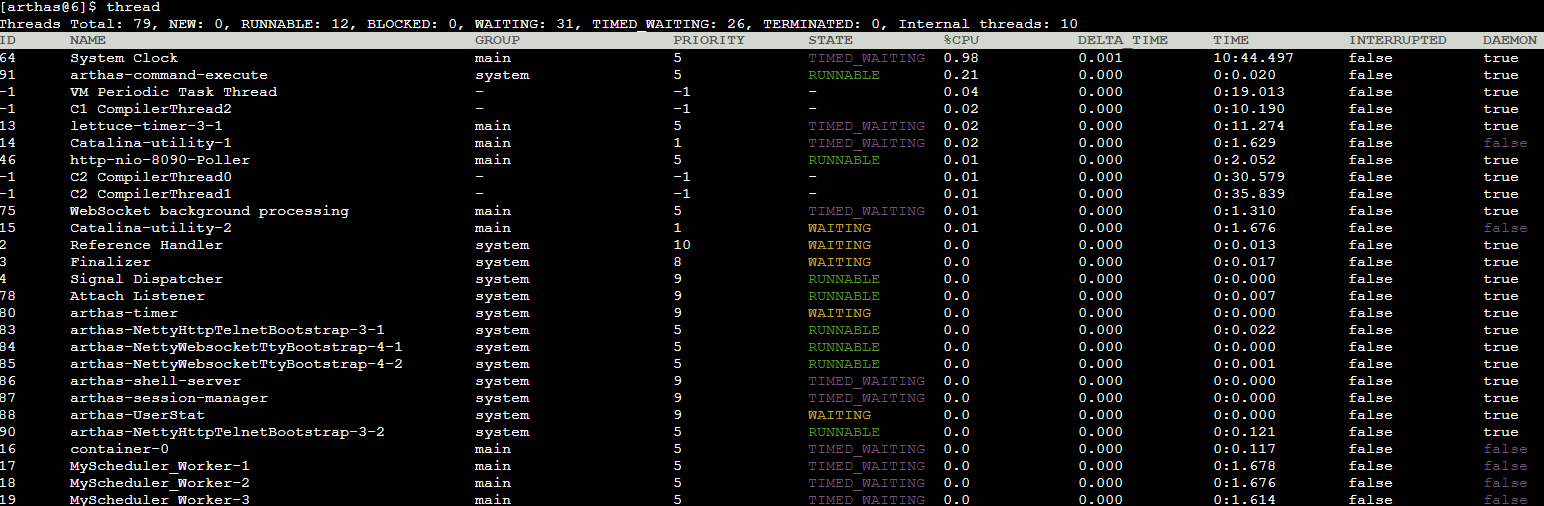
找出 CPU 占用前列的线程 ID,通过 thread id 命令, 显示指定线程的运行堆栈,排查堆栈上方法的代码,解决问题!
1 | BASH |

结论
本文记录了真实工作中的一次线上问题诊断过程,代码中因 while 循坏条件设置不合理导致死循环,不停地创建 Date 对象,导致内存泄漏和 CPU 飙升…
借助 Arthas 这款线上问题诊断神器,能够快速地定位到问题,在容器中可能会踩几个坑,好在最终还是解决了问题!








